It is the process of using Industry knowledge to extract features from raw data. These features can be used to improve the performance of machine learning algorithms.
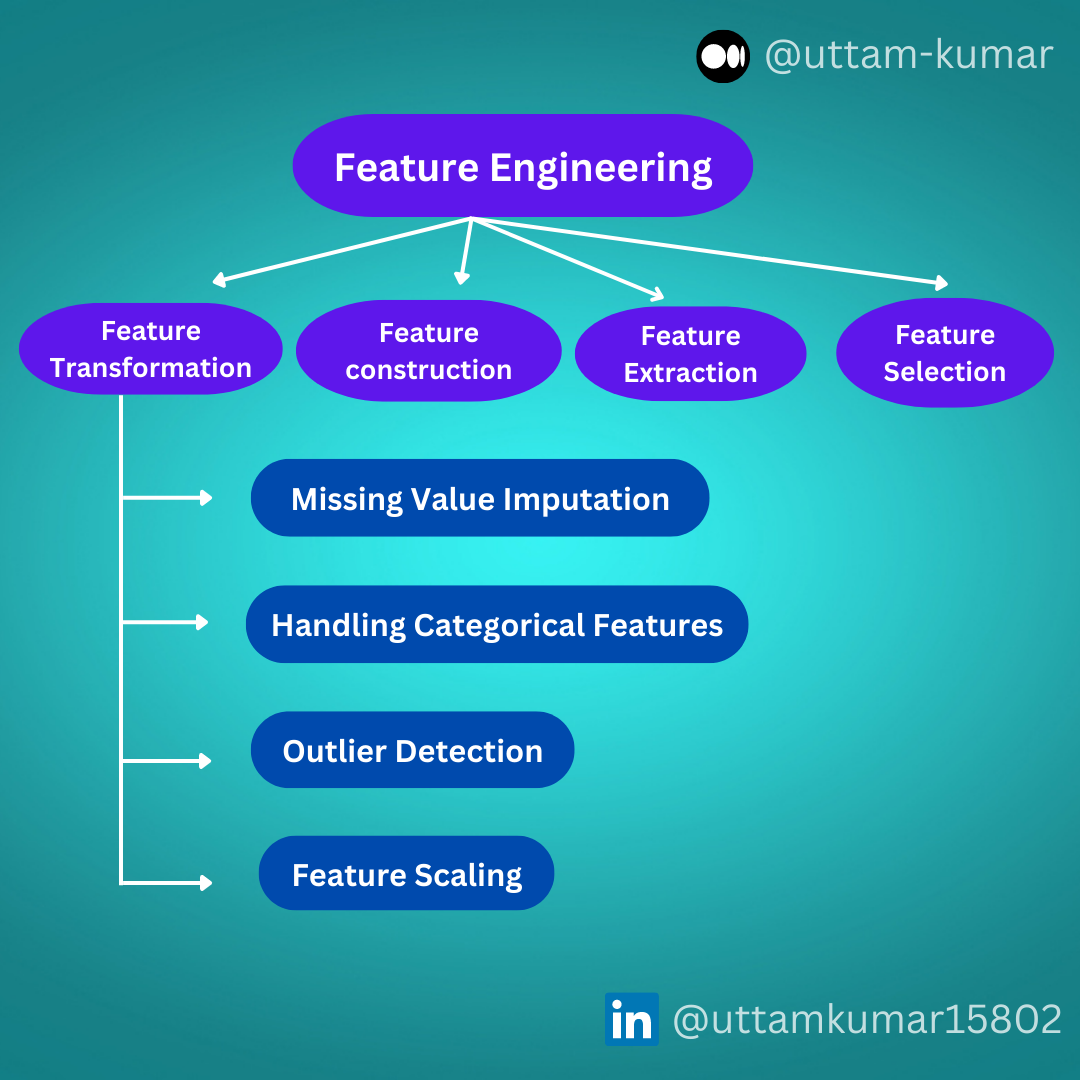
Feature engineering consists of creation, transformation, extraction, and selection of features that are used to create an accurate ML algorithm.
Feature Engineering is very important because it can affect your model. It has been said if you give good labels data to a bad algorithm then it can perform better but if you give a bad data to a good algorithm then it will not perform better.
Feature Engineering is not something that you can learn in any book, of course there are some general ways how you should deal with that particular problem. But, experience and domain knowledge plays a crucial role in Feature Engineering.
Now, Let’s talk about the Feature Engineering types in detail :-
Feature Transformation
Feature Construction
Feature Extraction
Feature Selection
Feature Transformation further also divided into :-
Missing Value Imputation
Handling Categorical Features
Outlier Detection
Feature Scaling
Feature Transformation
Feature Transformation is a technique in which we apply mathematical formulas to a particular column (feature) to transform the values so that performance of the model increases.
Feature Transformation is one of the important tasks in the whole process because most of the time the dataset you will get will not be of the same magnitude so you have to scale down the values.
In simple words, If we have a column which we think is not performing better, we do changes in that so it is known as feature transformation.
When the data of a particular feature(column) is not normally distributed then we take log, so that it becomes normally distributed.
Missing Values Imputation
Missing Values are found in all dataset and it is represented by question mark, special character or any other special symbol. If we delete those values then some important data can be missing and it is possible that some important aspect can be untouched.
So, that’s why handling missing values is important. We can use mean or mode to handle missing values.
For example :- Taking average age where null values are there.
There are some other techniques also in Machine Learning where you just have to call the function and all the work done by the function.
For Example :- SimpleImputer in sklearn i.e., used to handle both numerical and categorical values.
Handling Categorical Features
We can take the mean of the numerical values and also perform statistical operations on the Numerical values but not on the categorical values. Machine Learning models need numerical values that do not perform on categorical values. Here, we have to convert categorical values into numerical values.
One most famous technique to handle categorical values is One Hot Encoding.
Here, we take unique values of the categorical column and make a column of each unique value. You can easily understand the image below.
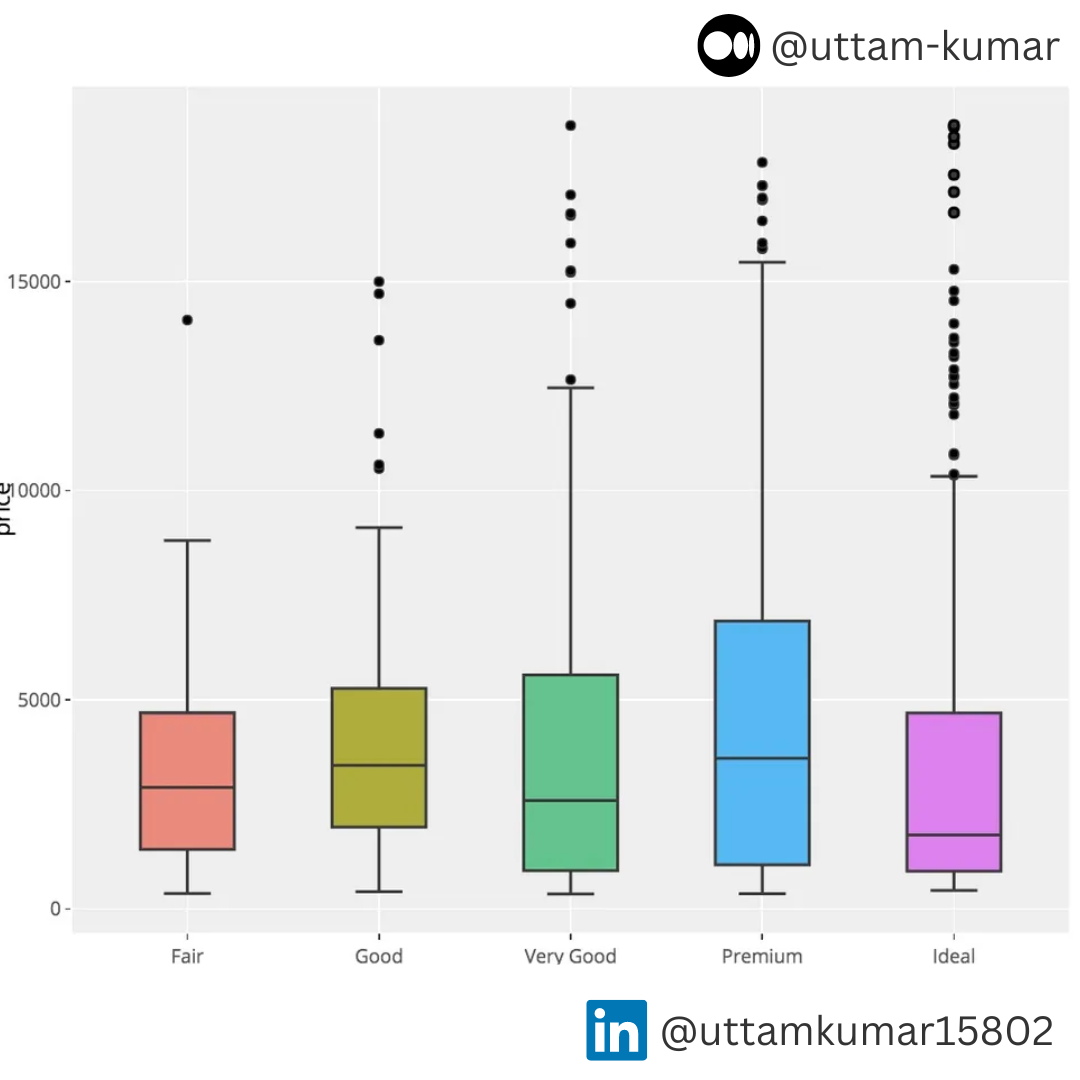
Outlier Detection
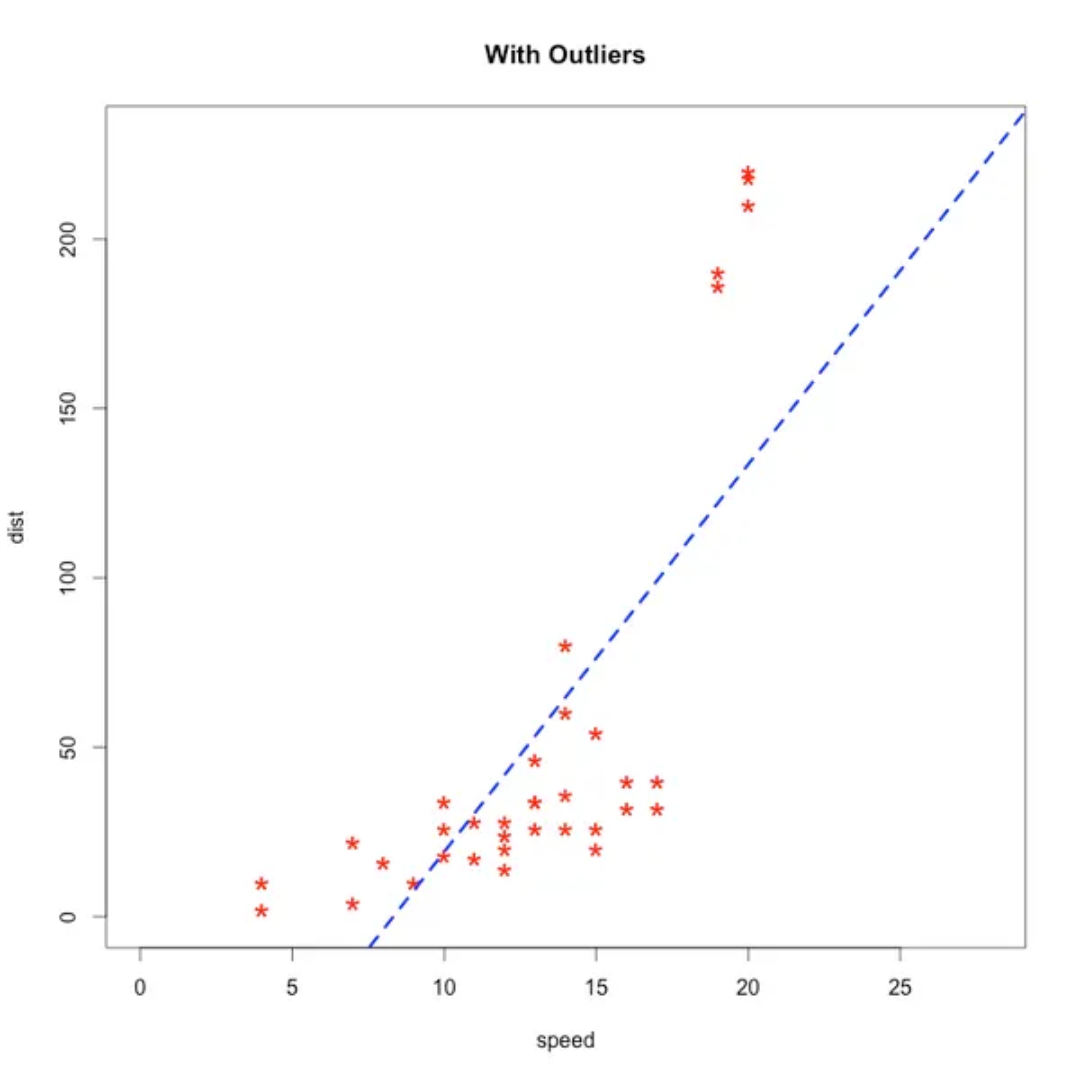
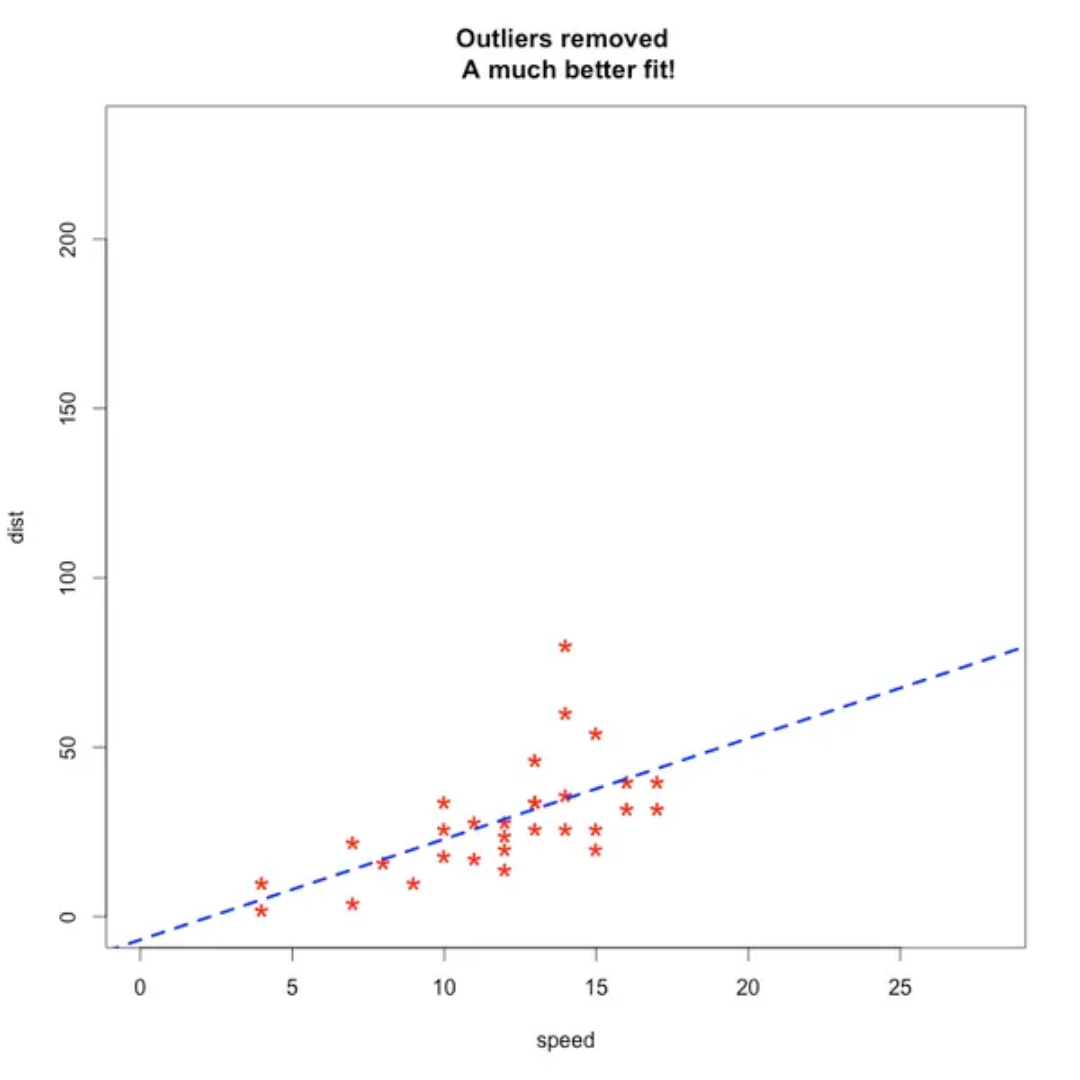
Outliers are the observations that are very different from the rest of the observations, you can simply say that these are totally different from the rest.
We have to detect the outliers because outliers affected the machine learning model. If there will be outliers in the dataset then it can affect the prediction of the model and bias the result.
We can understand this from the below example,
With Outliers
Without Outliers
We should treat the outliers and there are some techniques like Boxplot where we can spot the outliers. The points which are not in the box area are the outliers. We can understand this from the image below.
Feature Scaling
Feature scaling is a technique to standardize the independent Features. Feature scaling is generally performed in the data preprocessing steps.
If we don’t perform feature scaling then it is going to affect the model performance and if we perform feature scaling then it improves the model performance.
Feature Scaling are of two types:-
Standardization
Normalization
When we are working with the KNN that works on the distance between points. So, here by using feature scaling model performance will be performed.
Feature Construction
In Feature Construction we add a sibling and parent column to make a new family column. Here we make a new column from the existing ones.
It comes from the experience when you have worked on some of the dataset then you will easily identify where you should add columns and domain knowledge also plays a role.
Example :- In the titanic dataset, no of siblings and parents are in different columns, here we can make a separate column where we can classify it as a small, big family.
Feature Selection
Feature selection plays an important role when we pass the columns into the machine learning models, here you have to decide which column is necessary and which are not so that you only consider the important column so that your machine learning model accuracy can be improved.
It simply reduces the inputs and helps in finding important features.
In Feature Selection we select the important columns that are actually affecting the outcome and consider that for further analysis.
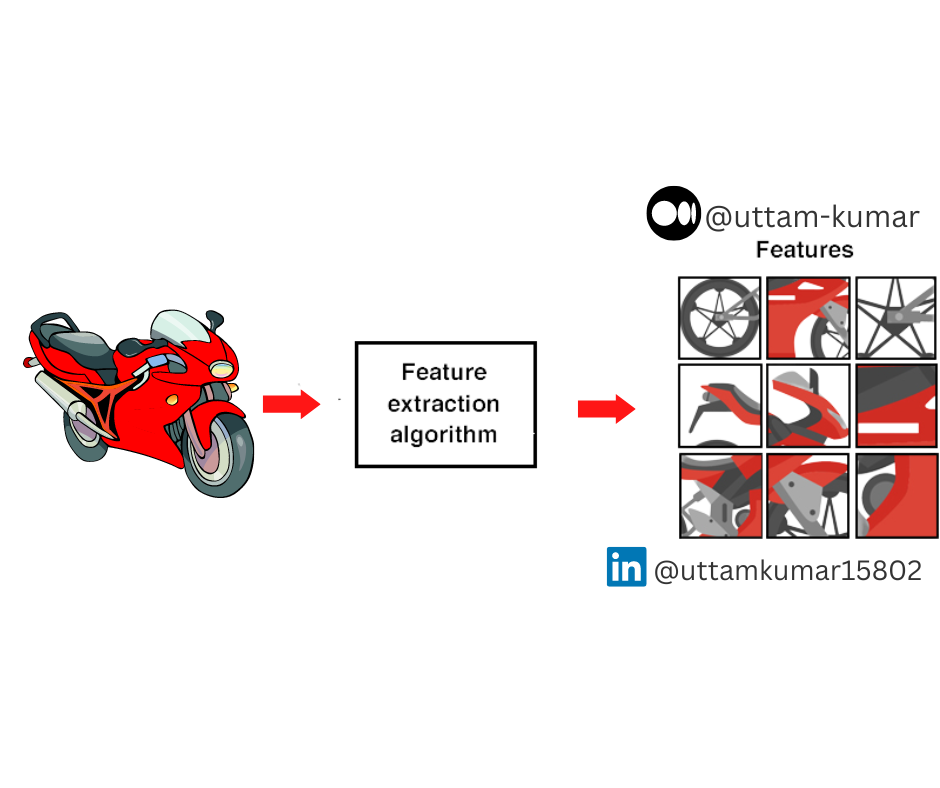
Feature Extraction
Feature Extraction is different from feature scaling. It is a part of dimensionality reduction which comes in unsupervised learning. In feature extraction raw data is processed and reduced into smaller features to more manageable groups for preprocessing.
When we apply feature extraction on the dataset then training speed increases and it also reduces the probability of overfitting. Feature extraction also helps in improving model accuracy.
Here, in the above picture, instead of giving whole bike photo we give photos of specific parts of bike which helps it increase performance.
This was all about of Feature Engineering, where we talk about Feature Engineering and it’s types along with examples. Feature Engineering plays an important role in Data Analysis.
I suggest to read more about the Feature Engineering and apply your knowledge on the dataset.



0 Comments
If you have doubt, let us know...